QuantEvolve: LLM 멀티 에이전트가 퀀트 전략을 '진화'시키는 법
AlphaEvolve의 퀀트 버전. LLM 멀티 에이전트 + 진화 알고리즘으로 트레이딩 전략을 자동 생성·진화시키는 QuantEvolve 프레임워크 논문 리뷰.
AlphaEvolve가 수학 문제를 풀었다면, QuantEvolve는 트레이딩 전략을 진화시킨다. ACM ICAIF 2025에서 구두 발표된 이 논문은 LLM 멀티 에이전트 + 진화 알고리즘으로 퀀트 전략을 자동 생성하는 프레임워크를 제안한다.
문제: 왜 기존 방식은 한계가 있나?
기존 LLM 기반 퀀트 시스템(AlphaGPT, R&D-Agent-Quant 등)은 알파 팩터 발굴에 집중한다. 개별 시그널을 찾는 건 잘하지만, 포지션 사이징·리스크 관리·실행 로직까지 포함한 완전한 전략(end-to-end strategy)을 만들지는 못한다. 또한 하나의 "최적 전략"만 추구하다 보면 시장 레짐 변화에 취약해진다.
QuantEvolve의 핵심 아이디어
1. Quality-Diversity 진화: Feature Map

Figure 1: QuantEvolve 프레임워크 아키텍처
전략을 단일 목적함수로 최적화하는 대신, Feature Map이라는 다차원 그리드에 전략들을 배치한다. 각 차원은 투자자 선호도와 연결된다:
- 전략 카테고리 (모멘텀, 평균회귀, 차익거래 등 — 바이너리 인코딩)
- 샤프 비율 (리스크 대비 수익)
- 최대 낙폭(MDD)
- 거래 빈도
- 누적 수익률
각 셀에는 해당 특성 조합에서 가장 좋은 전략 하나만 저장된다. 덕분에 다양한 리스크-수익 프로파일의 전략이 공존하며, 특정 전략에 수렴하는 것(mode collapse)을 방지한다.
2. Island Model: 탐색과 수렴의 균형

Figure 3: 아일랜드 간 전략 교환
여러 "섬(Island)"에서 독립적으로 전략이 진화하되, 주기적으로 상위 10% 전략을 이웃 섬으로 이주(migration)시킨다. 초기에는 각 섬이 모멘텀, 평균회귀 등 전문화된 전략을 깊이 파고, 후기에는 교차 수분을 통해 하이브리드 전략이 출현한다.
3. 가설 기반 멀티 에이전트 시스템

Figure 2: 멀티 에이전트 진화 아키텍처
전략 생성은 3단계 에이전트 파이프라인으로 이루어진다:
- Research Agent — 부모·사촌 전략 분석 → 새 가설 생성 (금융 이론 기반)
- Coding Team — 가설을 Python 코드로 구현 → Zipline 백테스트 → 반복 디버깅
- Evaluation Team — 가설·코드·결과 분석 → 인사이트 추출 → 미래 세대에 전달
핵심은 인사이트 축적이다. 실패한 30+ 접근법을 기록하고, "왜 실패했는지"까지 문서화하여 같은 실수를 반복하지 않는다. 순수 랜덤 돌연변이 대비 훨씬 효율적인 탐색이 가능하다.
4. 부모-사촌 샘플링
새 전략을 만들 때 Feature Map에서 부모 전략 1개 + 사촌 전략 7개를 선택한다:
- Best Cousins (2개): 고성과 전략
- Diverse Cousins (3개): Feature Space에서 부모와 인접한 전략
- Random Cousins (2개): 무작위
이 구조가 exploitation(고성과 계승)과 exploration(새로운 조합 탐색)을 동시에 달성한다.
실험 결과
주식 시장 (AAPL, MSFT, AMZN, GOOGL, META, NVDA)
진화 과정이 인상적이다:

Figure 7: 주식 시장에서 최적 전략의 진화 과정
- Gen 0: 볼륨-모멘텀 시그널 (단순)
- Gen 10: 멀티 타임프레임 모멘텀 + 변동성 필터링 → 수익↑ 낙폭↑
- Gen 40: 포트폴리오 레벨 변동성 모니터링 도입 → 낙폭↓
- Gen 80: 공적분 페어 트레이딩 시도 → 실패 (변동성 기간 공적분 불안정)
- Gen 130: 이전 세대의 성공 요소만 선택적 통합 → 모멘텀 진입 + 변동성 스케일링 + 트레일링 스탑
최종 전략이 MarketCap, Equal Weight, Risk Parity, RSI, MACD 베이스라인 모두를 아웃퍼폼.
선물 시장 (ES, NQ)

Figure 9: 선물 시장에서의 전략 진화
- Gen 0: 고정 볼린저밴드 평균회귀 → SR -1.21 (참사)
- Gen 10: 적응형 Z-스코어 + 모멘텀 확인 → MDD -15%로 개선
- Gen 20: 듀얼 모드 레짐 감지 — 저변동성→평균회귀, 고변동성→모멘텀 추종
- SR 1.03 | CR 37.4% | MDD -15.4%
- ES(SR 0.66)와 NQ(SR 0.97) 바이앤홀드 모두 초과
흥미로운 점: Gen 20 이후 세대들이 더 복잡한 시스템을 만들었지만 일반화 성능은 오히려 하락했다. 단순함이 정교함을 이긴 전형적인 bias-variance tradeoff 사례.
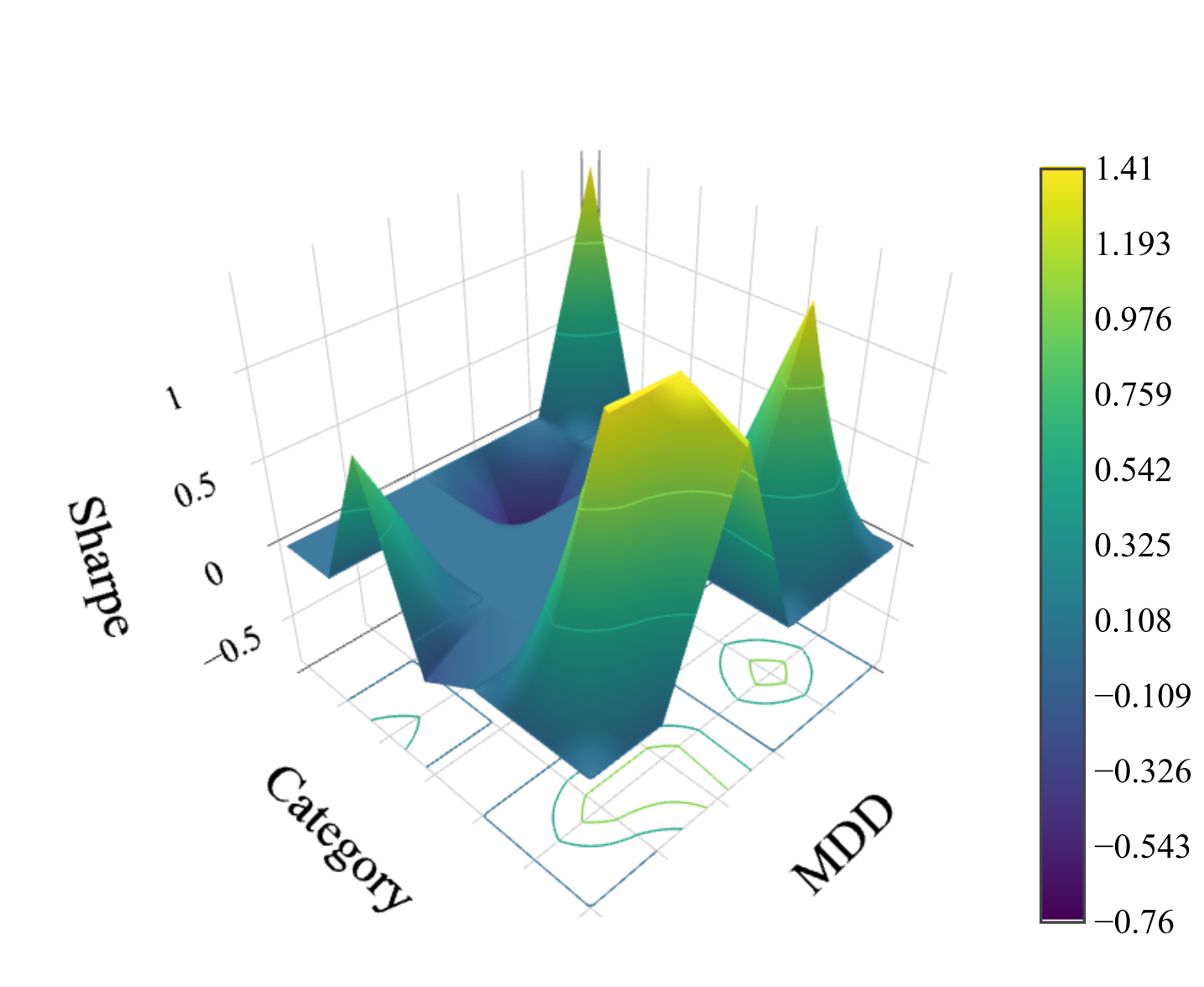
Feature Map 진화 과정

Figure 5: Feature Map의 세대별 진화 (MDD × Category 차원, Sharpe Ratio 기준)
Gen 0에서 거의 비어있던 Feature Map이 Gen 150까지 점진적으로 채워지며, 각 셀의 성능도 꾸준히 향상된다.
인사이트 진화

Figure 8: 주식 시장에서의 인사이트 진화 과정
이 프레임워크의 진짜 가치는 전략 자체보다 축적된 인사이트에 있을 수 있다:
- "단순 변동성 지표는 위기 시 실패" → VIX + 이동평균 결합 필요
- "변동성 임계값은 포트폴리오가 아닌 자산별로 계산해야"
- "레짐 감지 실패는 변동성 연율화 오류 때문 (로직 자체는 유효)"
- 30+ 실패 접근법 문서화 → 미래 세대가 같은 함정 회피
기술 스택
- LLM: Qwen3-30B-A3B (빠른 응답) + Qwen3-Next-80B-A3B (심층 분석) 앙상블
- 백테스트: Zipline Reloaded + QuantStats
- 진화 점수: Score = Sharpe Ratio + Information Ratio + MDD (동일 가중)
한계와 생각할 거리
- 데이터 Universe가 작다 — 주식 6개, 선물 2개. 실전 적용 시 수백 종목 스케일링이 관건
- 오버피팅 리스크 — 논문 자체도 Gen 20 이후 복잡성 증가 시 성능 저하를 보고
- 실행 비용 미반영 — Zipline 시뮬레이션은 실제 슬리피지/마켓 임팩트와 차이
- LLM 비용 — 150세대 × 다중 에이전트 = 상당한 API 비용 (구체적 미공개)
시사점
QuantEvolve는 "AI가 트레이딩 전략을 발명한다"는 비전의 가장 구체적인 구현 중 하나다. 특히:
- 단일 최적 전략 추구 → 다양한 전략 풀 유지라는 패러다임 전환
- 실패 기록의 가치 — 30+ 실패 접근법이 미래 탐색 효율을 극적으로 높임
- 단순함의 승리 — 복잡한 후기 세대보다 적절히 복잡한 중간 세대가 더 잘 일반화
퀀트 트레이딩에 LLM을 활용하려는 사람이라면 반드시 읽어볼 논문이다.
논문: QuantEvolve: Automating Quantitative Strategy Discovery through Multi-Agent Evolutionary Framework
저자: Junhyeog Yun, Hyoun Jun Lee, Insu Jeon
발표: ACM ICAIF 2025 (AI4F Workshop, Oral Presentation)