QuantEvolve:LLMマルチエージェントがクオンツ戦略を'進化'させる方法
AlphaEvolveのクオンツ版。LLMマルチエージェント+進化アルゴリズムでトレーディング戦略を自動生成・進化させるQuantEvolveフレームワーク論文レビュー。
AlphaEvolveが数学の問題を解いたなら、QuantEvolveはトレーディング戦略を進化させる。ACM ICAIF 2025で口頭発表されたこの論文は、LLMマルチエージェント+進化アルゴリズムでクオンツ戦略を自動生成するフレームワークを提案する。
問題:なぜ既存の方法には限界があるのか?
既存のLLMベースクオンツシステム(AlphaGPT、R&D-Agent-Quant等)はアルファファクター発掘に集中している。個別シグナルの発見は得意だが、ポジションサイジング・リスク管理・執行ロジックまで含んだ完全な戦略(end-to-end strategy)は作れない。また一つの「最適戦略」だけを追求すると、市場レジーム変化に脆弱になる。
QuantEvolveの核心アイデア
1. Quality-Diversity進化:Feature Map

Figure 1: QuantEvolve フレームワークアーキテクチャ
戦略を単一目的関数で最適化する代わりに、Feature Mapという多次元グリッドに戦略を配置する。各次元は投資家の選好と連結される:
- 戦略カテゴリ(モメンタム、平均回帰、裁定取引等 — バイナリエンコーディング)
- シャープレシオ(リスク対比リターン)
- 最大ドローダウン(MDD)
- 取引頻度
- 累積リターン
各セルには当該特性の組み合わせで最も優れた戦略1つのみ保存される。これにより多様なリスク・リターンプロファイルの戦略が共存し、特定戦略への収束(mode collapse)を防止する。
2. Island Model:探索と収束のバランス

Figure 3: アイランド間の戦略交換
複数の「島(Island)」で独立的に戦略が進化しつつ、定期的に上位10%の戦略を隣接する島へ移住(migration)させる。初期には各島がモメンタム、平均回帰等の専門化された戦略を深掘りし、後期には交差受粉を通じてハイブリッド戦略が出現する。
3. 仮説ベースのマルチエージェントシステム

Figure 2: マルチエージェント進化アーキテクチャ
戦略生成は3段階のエージェントパイプラインで行われる:
- Research Agent — 親・いとこ戦略を分析 → 新仮説を生成(金融理論ベース)
- Coding Team — 仮説をPythonコードで実装 → Ziplineバックテスト → 反復デバッグ
- Evaluation Team — 仮説・コード・結果を分析 → インサイトを抽出 → 将来世代に伝達
核心はインサイトの蓄積だ。失敗した30以上のアプローチを記録し、「なぜ失敗したか」まで文書化して同じミスを繰り返さない。純粋なランダム突然変異と比べ、はるかに効率的な探索が可能になる。
4. 親-いとこサンプリング
新戦略を作る際、Feature Mapから親戦略1つ+いとこ戦略7つを選択する:
- Best Cousins(2つ):高パフォーマンス戦略
- Diverse Cousins(3つ):Feature Spaceで親と隣接する戦略
- Random Cousins(2つ):ランダム
この構造がexploitation(高パフォーマンス継承)とexploration(新しい組み合わせの探索)を同時に達成する。
実験結果
株式市場(AAPL, MSFT, AMZN, GOOGL, META, NVDA)
進化過程が印象的だ:

Figure 7: 株式市場における最適戦略の進化過程
- Gen 0: ボリューム-モメンタムシグナル(シンプル)
- Gen 10: マルチタイムフレームモメンタム+ボラティリティフィルタリング → リターン↑ ドローダウン↑
- Gen 40: ポートフォリオレベルのボラティリティモニタリング導入 → ドローダウン↓
- Gen 80: 共和分ペアトレーディング試行 → 失敗(ボラティリティ期間は共和分が不安定)
- Gen 130: 過去世代の成功要素のみ選択的統合 → モメンタムエントリー+ボラティリティスケーリング+トレーリングストップ
最終戦略がMarketCap、Equal Weight、Risk Parity、RSI、MACDベースライン全てをアウトパフォーム。
先物市場(ES, NQ)

Figure 9: 先物市場における戦略進化
- Gen 0: 固定ボリンジャーバンド平均回帰 → SR -1.21(惨事)
- Gen 10: 適応型Zスコア+モメンタム確認 → MDD -15%に改善
- Gen 20: デュアルモードレジーム検知 — 低ボラティリティ→平均回帰、高ボラティリティ→モメンタム追従
- SR 1.03 | CR 37.4% | MDD -15.4%
- ES(SR 0.66)とNQ(SR 0.97)のバイアンドホールドを双方超過
興味深い点:Gen 20以降の世代がより複雑なシステムを構築したが、汎化性能はむしろ低下した。シンプルさが精巧さに勝った典型的なbias-variance tradeoffの事例。
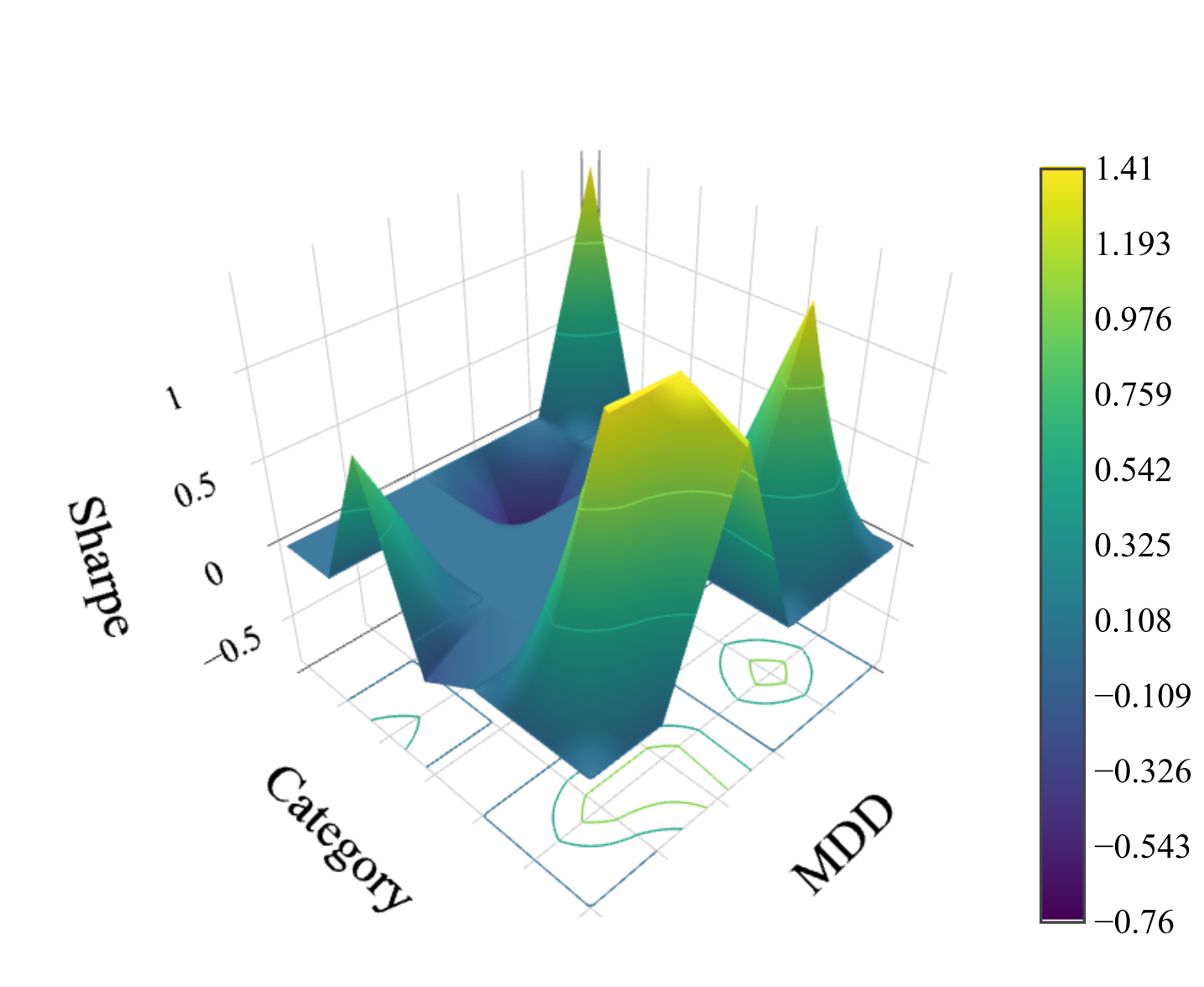
Feature Map進化過程

Figure 5: Feature Mapの世代別進化(MDD × Category次元、Sharpe Ratio基準)
Gen 0でほぼ空だったFeature MapがGen 150まで段階的に埋まり、各セルの性能も着実に向上する。
インサイトの進化

Figure 8: 株式市場におけるインサイト進化過程
このフレームワークの真の価値は、戦略そのものより蓄積されたインサイトにあるかもしれない:
- 「単純なボラティリティ指標は危機時に失敗」→ VIX+移動平均の結合が必要
- 「ボラティリティ閾値はポートフォリオではなく資産別に計算すべき」
- 「レジーム検知の失敗はボラティリティ年率化の誤りが原因(ロジック自体は有効)」
- 30以上の失敗アプローチを文書化 → 将来世代が同じ罠を回避
技術スタック
- LLM: Qwen3-30B-A3B(高速応答)+ Qwen3-Next-80B-A3B(深層分析)アンサンブル
- バックテスト: Zipline Reloaded + QuantStats
- 進化スコア: Score = Sharpe Ratio + Information Ratio + MDD(等加重)
限界と考えるべきこと
- データユニバースが小さい — 株式6銘柄、先物2銘柄。実戦適用時は数百銘柄へのスケーリングが課題
- オーバーフィッティングリスク — 論文自体もGen 20以降の複雑性増加時に性能低下を報告
- 執行コスト未反映 — Ziplineシミュレーションは実際のスリッページ・マーケットインパクトと乖離
- LLMコスト — 150世代×マルチエージェント=相当なAPIコスト(具体的金額は未公開)
示唆
QuantEvolveは「AIがトレーディング戦略を発明する」というビジョンの最も具体的な実装の一つだ。特に:
- 単一最適戦略の追求 → 多様な戦略プールの維持というパラダイムシフト
- 失敗記録の価値 — 30以上の失敗アプローチが将来の探索効率を劇的に向上
- シンプルさの勝利 — 複雑な後期世代より適度に複雑な中間世代がより良く汎化
クオンツトレーディングにLLMを活用しようとする人なら、必読の論文だ。
論文: QuantEvolve: Automating Quantitative Strategy Discovery through Multi-Agent Evolutionary Framework
著者: Junhyeog Yun, Hyoun Jun Lee, Insu Jeon
発表: ACM ICAIF 2025(AI4F Workshop, Oral Presentation)